So, while I deploy my bespoke python code to scrape the contents of umpteen WordPress and Blogger blogs, I’ve continued trying to classify blogs from my sample according the the categories I outlined in my previous post.
I say ‘trying’ because it’s not as straightforward as it seems. Some blogs clearly don’t fit into any of the categories, e.g. where a blogger has simply written about their holiday, or for one blogger written a series of posts explaining various aspects of science or physics. I reckon that this a science teacher writing for the benefit of his or her students, but as the posts are sharing ‘knowledge’ rather than ‘resources’, I can’t classify them. Fortunately the label propagation algorithm I will eventually be using will allow for new categories to be instigated (or the ‘boundaries’ for existing categories to be softened) so it shouldn’t be a problem.
‘Soapboxing’, ‘professional concern’ and ‘positioning’ have also caused me to think carefully about my definitions. ‘Soapboxing’ I’m counting as all posts that express an opinion in a strident, one-sided way, with a strong feeling that the writer is venting frustration, and perhaps with a call to action. These tend to be short posts, probably written because the blogger simply needs to get something off their chest and (possibly, presumably) get some support from others via the comments. ‘Professional concern’, then, is a also post expressing a view or concern, but the language will be more measured. Perhaps evidence from research or other bloggers will be cited, and the post will generally be longer. The blogger may identify themselves as a teacher of some experience, or perhaps a head of department or other school leader. As with ‘soapboxing’, a point of view will be expressed, but the call to action will be absent.
‘Positioning’ is a blog post that expresses a belief or method that the blogger holds to be valid above others, and expresses this as a series of statements. Evidence to support the statements will be present, generally in the form of books or published research by educational theorists or other leading experts in the field of education.
Of course, having made some decisions regarding which blogs fit into these categories, I need to go back through some specific examples and try to identify some specific words or phrases that exemplify my decision. And I fully expect other people to disagree with me, and be able to articulate excellent reasons why blog A is an example of ‘positioning’ rather than ‘professional concern’, but all I can say in response is that, while it’s possible to get a group of humans to agree around 75% of the time, it’s impossible to get them to agree 100%, and that’s but the joy and the curse of this kind of research.
Given more time, I’d choose some edu-people from Twitter and ask them to categorise a sample of blogs to verify (or otherwise) my decision, but as I don’t have that luxury the best I can do is make my definitions as clear as possible, and provide a range of examples as justification.
The other categories that aren’t proving straightforward are ‘feeedback, assessment and marking’ (‘FAM’) and ‘behaviour’. I knew this might be the case, though, so I’m keeping an open mind about these. I have seen examples of blogs discussing ‘behaviour’ that I’ve put into one of the three categories I’ve mentioned above, but that’s because the blogs don’t discuss ‘behaviour’ exclusively.
Anyway, I’ve categorised 284 (out of a total of 7,788) posts so far so I thought I’d have a bit of a look at the data.
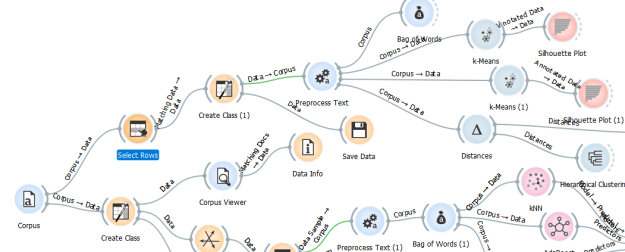
I used Orange again to get a bit more insight into my data. Just looking at the top flow, after opening the corpus I selected the rows that had something entered in the ‘group’ column I created.

Selecting rows.

Creating classes.
I then created a class for each group name. This additional information can be saved, and I’ve dragged the ‘save data’ icon onto the workspace, but I’ve chosen not to save it automatically for now. If you do, and you give it a file name, every time you open Orange the file will be overwritten, which you may not want. Then, I pre-processed the 284 blogs using the snowball stemmer, and decided I’d have a look at how just the sample might be clustered using k-means.
“Since it effectively provides a ‘suffix STRIPPER GRAMmar’, I had toyed with the idea of calling it ‘strippergram’, but good sense has prevailed, and so it is ‘Snowball’ named as a tribute to SNOBOL, the excellent string handling language of Messrs Farber, Griswold, Poage and Polonsky from the 1960s.”
Martin Porter
I’m not sure if I’ve explained k-means before, but here’s a nice link that explains it well.
“Clustering is a technique for finding similarity groups in a data, called clusters. It attempts to group individuals in a population together by similarity, but not driven by a specific purpose.”
The data points are generated from the words in the blogs. These have been reduced to tokens by the stemmer, then a count is made of the number of times each word is used in a post. The count is subsequently adjusted to take account of the length of the document so that a word used three times in a document of 50 words is not given undue weight compared with the same word used three times in a document of 500. So, each document generates a score for each word used, with zero for a word not used that appears in another document or documents. Mathematical things happen and the algorithm coverts each document into a data point in a graph like the ones in the link. K-means then clusters the documents according to how similar they are.
I already know I have 8 classes, so that’s the number of clusters I’m looking for. If I deploy the algorithm, I can see the result on a silhouette plot (the matching icon, top far right of the flow diagram above). The closer to a score of ‘0’, the more likely it is that a blog post is on the border between two clusters. When I select that the silhouette plot groups each post by cluster, it’s clear that ‘resources’ has a few blogs that are borderline.


‘FAM’ and ‘behaviour’ are more clearly demarcated. If I let the algorithm choose the optimal number of clusters (Orange allows between 2 and 30), the result is 6, although 8 has a score of 0.708 which is reasonable (as you can see, the closer to 1 the score is, the higher the probability that the number suggested is the ‘best fit’ for the total number of clusters within the data set).
 As you can see from the screenshot below, cluster 4 is made up of posts from nearly all the groups. Remember, though, that this algorithm is taking absolutely no notice of my categories, or the actual words as words that convey meaning. It’s just doing what it does based on numbers, and providing me with a bit of an insight into my data.
As you can see from the screenshot below, cluster 4 is made up of posts from nearly all the groups. Remember, though, that this algorithm is taking absolutely no notice of my categories, or the actual words as words that convey meaning. It’s just doing what it does based on numbers, and providing me with a bit of an insight into my data.






