
Apache Cassandra is a free and open-source distributed NoSQL database management system designed to handle large amounts of data across many commodity servers, providing high availability with no single point of failure.
It is a peer to peer database where each node in the cluster constantly communicates with each other to share and receive information (node status, data ranges and so on). There is no concept of master or slave in a Cassandra cluster.Any Node can be coordinator node for each query.
In this blog, we’ll take a look behind the scenes to see how Cassandra handles write queries. For Cassandra Basics and installation, you can refer to our earlier blog.
Writing in CassandraWhen a client performs a write operation against a Cassandra database, it processes data at several stages on the write path, starting with the immediate logging of a write and ending in with a write of data to disk:
- Logging data in the commit log
- Writing data to the memtable
- Flushing data from the memtable
- If a crash occurs before the MemTable got flushed to disk, the commit log is used to replay that data and to rebuild the MemTable. All data successfully written to disk during the flush operation is then removed from the commit log.
- Storing data on disk in SSTables
- SSTables are immutable and can not be altered/changed post data insertion.
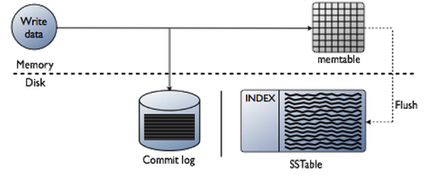
Cassandra Interactions on the write path
The write path describes how data modification queries initiated by clients are processed, eventually resulting in the data being stored on disk.
For nodes in the same local data center of the coordinator, the coordinator sends a write request to all replicas that own the row being written.
As long as all replica nodes are up and available, they will get the write regardless of the consistency level specified by the client. The write consistency level determines how many replica nodes must respond with a success acknowledgment in order for the write to be considered successful.
When a node writes and responds, that means it has written to the commit log and puts the mutation into a memtable.
Interactions between nodes on the write path
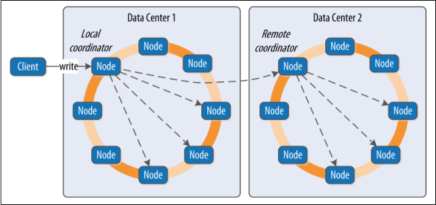
If the cluster spans multiple data centers, the local coordinator node selects a remote coordinator in each of the other data centers to coordinate the write to the replicas in that data center. Each of the remote replicas responds directly to the original coordinator node.
The coordinator waits for the replicas to respond. Once a sufficient number of replicas have responded to satisfy the consistency level, the coordinator acknowledges the write to the client. If a replica doesn’t respond within the timeout, it is presumed to be down, and a hint is stored for the write.
Interactions within a node on the write path
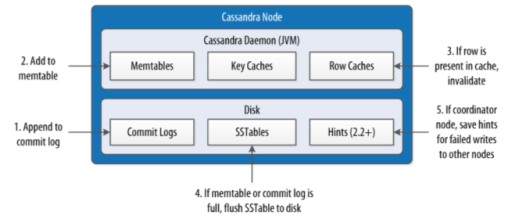
Within a node, for a write request :
the commit log.
Write Path Advantages
- Writing data to Cassandra is very fast as all the writes are append-only.
- The write path is one of Cassandra’s key strengths: for each Write Request one sequential disk write plus one in-memory write occur, both of which are extremely fast.
- During a write operation, Cassandra never reads before writing (with the exception of Counters and Materialized Views), never rewrites data, never deletes data and never performs random I/O. So, no chances of Data Corruption.

Cassandra also performs some special tasks during/after writing the data to Cassandra. These include :
- Compaction
- Hinted Handoff
- Caching
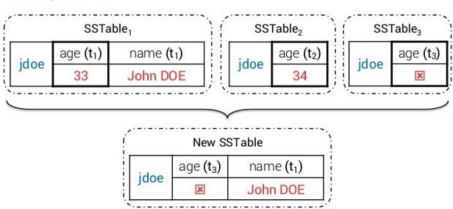
Compaction
Compaction in Apache Cassandra refers to the operation of merging multiple SSTables into a single new one.
This is done by merging rows and columns by partition key and time stamp. Only the latest version is merged into the new file. Deleted data (i.e. data marked with a tombstone) is dropped out.
After compaction, the old SSTables will be marked as obsolete. These SSTables are deleted asynchronously when JVM performs a GC, or when Cassandra restarts, whichever happens first.
Hinted Handoff
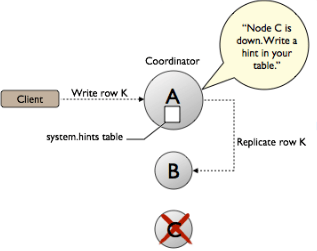
What if, when a write request comes to coordinator node and the actual node is down?
The coordinator stores a hint about the dead node on local system for a period of time (specified in the config file)
Whenever dead node recovers, the data is transferred to the recovered node.
One concern for hinted handoff is that a lot of hints may be created for a node which goes offline for quite some time. And once the node is back, it is going to be flooded by the hints. It is possible to disable hinted handoff or reduce the priority of hinted handoff messages to avoid this issue.
Caching

Cassandra includes integrated caching and distributes cache data around the cluster for you. The integrated cache solves the cold start problem by virtue of saving your cache to disk periodically and being able to read contents back in when it restarts. So you never have to start with a cold cache.
Basically, Cassandra provides with 2 major types of caching :

With proper tuning, hit rates of 85% or better are possible with Cassandra, and each hit on a key cache can save one disk seek per SSTable. Row caching, when feasible, can save the system from performing any disk seeks at all when fetching a cached row. Then, whenever growth in the read load begins to impact your hit rates, you can add capacity to quickly restore optimal levels of caching.
Thus, most high-profile Cassandra users like Netflix make heavy use of Cassandra’s key and row caches.
To Know more about how Cassandra handles its write operations, you can refer to the Cassandra Official Documentation.
In this blog, we basically tried to cover how Cassandra handles its write queries and how internally it tries to archive high throughput rates for write operations.
I hope you enjoyed reading this article.





