 In my last article I introduced you “Big Data“. With that in mind, you cannot keep yourself away from Hadoop. So what is Hadoop then?
In my last article I introduced you “Big Data“. With that in mind, you cannot keep yourself away from Hadoop. So what is Hadoop then?
Hadoop is an open source framework that provides storage of extremely large data sets and allows parallel processing of data over various clusters of commodity hardware. It has two major components:
Hadoop was created by Doug Cutting, the creator of Apache Lucene, the widely used text search library. Hadoop has its origins in Apache Nutch, an open source web search engine which itself is a part of the Lucene project. Actually Apache Nutch was started in 2002 for working crawler and search system but the Nutch Architecture would not scale up to billions of pages on the web.
In 2003 help came at hand when Google published a paper that described the architecture of Google’s distributed file system called GFS that was to solve Google’s storage needs for extremely large files generated as part of web crawl and indexing process. In 2004, they set out to write an open source implementation called the Nutch Distributed Filesystem (NDFS). Then in 2004, Google published another paper that introduced MapReduce to the world. Early in 2005, Nutch developers had a working MapReduce implementation in Nutch and by the middle of 2005, all major Nutch algorithms had been ported to run using MapReduce and NDFS.
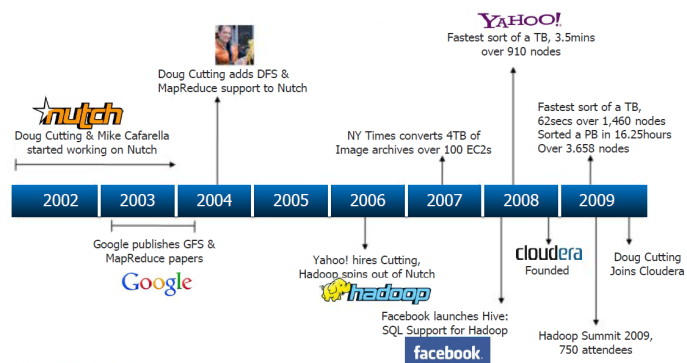
In February 2006 they moved out of Nutch to form an independent subproject of Lucene called Hadoop. At around the same time, Doug Cutting joined Yahoo!, that provided a dedicated team and the resources to turn Hadoop into a system that ran at web scale. This was demonstrated in February 2008 when Yahoo! announced that its production search index was being generated by a 10,000-core Hadoop cluster.
In January 2008, Hadoop was made its own top-level project at Apache, confirming its success and its diverse, active community. By this time, Hadoop was being used by many other companies besides Yahoo!, such as Last.fm, Facebook, and the New York Times.
In April 2008, Hadoop broke a world record to become the fastest system to sort a terabyte of data. Running on a 910-node cluster, it sorted one terabyte in 209 seconds (just under 3½ minutes), beating previous year’s winner of 297 seconds. In November of same year, Google reported that its MapReduce implementation sorted one terabyte in 68 seconds. As the first edition of this book was going to press (May 2009), it was announced that a team at Yahoo! used Hadoop to sort one terabyte in 62 seconds.
Benefits of using Hadoop- Computational Power: Hadoop’s distributed computing model allows processing of data fast. The more computing nodes you got, the more processing power you have.
- Scalability: With hadoop we can increase the storage capacity of cluster just by adding more nodes horizontally.
- Performance: One of the core feature in hadoop is distributed processing i.e the work load is shared by number of nodes and there is no burden on any particular node thus producing results extremely fast.
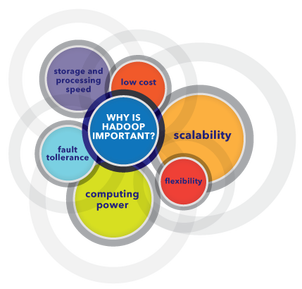
- Fault tolerance: Data and application processing are protected against hardware failure. If any node goes down, jobs are automatically redirected to other nodes to make sure the distributed computing does not fail and data is automatically re-replicated in preparation for future node failures.
- Flexibility: Unlike traditional relational databases, hadoop does not require to preprocess data before storing it. We can store any amount of data and of any type i.e structured, semi-structured and unstructured.
- Low cost: The open-source framework is free and uses commodity hardware to store large quantities of data.
So Hadoop is an open source platform that allows to store and process massive amounts of data quickly on clusters of commodity hardware. We can increase Hadoop’s computational power or storage just by adding more nodes to the cluster. In addition to that Hadoop is flexible in storing any data and is fault tolerant by automatically protecting data.
Happy Hadooping.
Share this:




