Object header, sync block, thin lock vs fat lock, hashcode – all of this and more will be explained in the following post.
First, let’s make a brief overview on the object header in the CLR.
What is the object header?

An header is – like it sound – header “above” the object.
If I try to illustrate it, it will be like this —->
Every object in CLR has an header that contains
info related to the object. The run -time use this info as we’ll see later in this post.
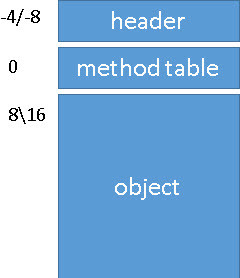
In memory, the header will sits in a negative offset from the object pointer: in a x86 (32 bit) process, the offset will be -4 bytes, and in a x64 process the offset will be -8 bytes.
(Keep in mind the although the offset changes from 4 bytes to 8 bytes, the sync block itself is always 4 bytes even in a 64 bit process.)
Why do we need the header?
The CLR uses that header to store a few things the run-time needs. Let’s start to reveal them, bit by bit.
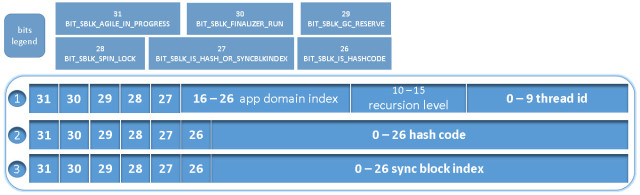
- 0 – 15: Thin lock information – 16 bits that are composed from 10 bits for thread id that’s holding the lock (0 mean no thread holding the lock) and 6 bits for recursion level (0 mean no lock was taken or only taken once by the same thread).
Thin lock meaning that all the lock info sits on the object header and that the sync block won’t create it (will explain the details later in this post) - 16 – 26: App domain index – 11 bits (2048 indices) index of the app domain that the object belongs to. (Set only when needed, e.g. for COM interop)
- 0 – 25: Sync block index – 26 bits: the index in the array of sync blocks (0 for shared sync block for all objects)
- 0 – 25: Hash code – 26 bits for object hashcode if not overridden
- 26: BIT_SBLK_IS_HASHCODE – 1 bit that marks if the rest of the word is a hash code or sync block index
- 27: BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX – 1 bit that tell us if hash code or sync block index are set
- 28: BIT_SBLK_SPIN_LOCK – 1 bit that is set if we want to lock the header for changing it value
- 29: BIT_SBLK_GC_RESERVE – 1 bit that is set only during the gc process, if the object is pinned
- 30: BIT_SBLK_FINALIZER_RUN – 1 bit that marks the object is finalized already (via GC.SuppressFinalize for example). When the finalizer thread is run, if this bit is turned on, it skip it (but always set it back to 0 to support “GC.RegisterForFinalization()”. Note that if it will remain turned on, the finalizer will skip it even if we ask to RegisterForFinalization)
- 31: BIT_SBLK_AGILE_IN_PROGRESS – Actually I’m not sure that I understand completely what this bit means, but it’s less important. In general this 1 bit is set only in debug build and it checks for infinite loop between two objects (object 1 has a ref to object 2 and object 2 has a ref to object 1)
There are 3 more markers that are used only for string type (0x80000000, 0x40000000 and 0xC0000000 if both are set). Note that in case of strings we use the BIT_SBLK_AGILE_IN_PROGRESS and BIT_SBLK_FINALIZER_RUN and its OK because we don’t need them in case of string (no meaning for infinite loop or finalizer in strings).
Sync BlockWhat’s the use of sync block index?
As you probably saw, in the above list there are more bytes than the header can store, and that’s why we have the bits flags that let us know which info is currently stored in the header.
If we want to store more info than the header can store (e.g. lock info and hash code for the object), there is another object called SyncBlock.
SyncBlock is a data structure that mainly stores info about thread synchronization (Monitor.Enter, Exit and Monitor.Wait, Pulse). But it also stores other info like hash code and app domain index. So, in case we don’t have enough space in the header, a SyncBlock will be created and all the info will be saved there. All sync blocks are stored in an array that’s accessible by index.
SyncBlock will be created in an additional case, when a kernel event object is involved and we need to store the handle to it in the SyncBlock.
This lock vs Fat lock
II’ll explain it in a few words. When we lock on some object, this lock called “thin lock” and we store only the thread id and the recursion level (how much times we enter the monitor from the same thread). Thin lock is stored in the object header if it is possible, if not (there is a computed hash code for this object), it will be store in sync block object and the lock will become a “fat lock”. Even if there isn’t a computed hash code for the object, there is a case when the lock becomes a “fat lock”. The cases are when contention occurs or when condition variable is involved (via Wait, Pulse etc.). Because for these cases, additional info need to be store – such as a handle to the kernel object or a list of events that are associated with the lock – and this is stored in a sync block.
Note that when using the thin lock, the lock operation is very fast. If it the first lock, just set the thread id and when contention occurs in most cases it just spins till the thread id in object header is zero then set to the new thread id. If it doesn’t succeed, sync block is created.
Return to sync block index
So the use of the sync block index is to point to the index of the sync block object in the array of sync blocks.
Sync block implementation
The actual implementation is a bit complicated (and I think also the comments in the code don’t always match the code itself and it makes it more difficult to understand).
If I simplify it, I can say that there is an array of sync blocks (SyncBlockArray) and there is a table of SyncTableEntry and a cache manager SyncBlockCache. Each sync block index points to the sync table entry that in turn points to the actual sync block and to the object. The cache responsibility is to allocate and release sync blocks in the array itself and in the entries table. Sync block is reclaimed by the GC when not needed but they are reusable.
Example to something that isn’t very clear to me is the following comments:
“many objects have a SyncTableEntry but no SyncBlock. That’s because someone (e.g. HashTable) called Hash() on them“
or:
“a common case (need a hash code for an object) you just need a syncTableEntry“
I don’t understand it because as I see it in the code, the hash code is stored in the header itself when possible or in the sync block itself, so how will a sync table entry will help here? Maybe I’m missing something here.
As a side note, what will happen if for example we need to create too many sync blocks entries? As you saw there are some limited bits to hold it. As other cases in software design, we need to decide how to handle each case (unlimited growth, override old, throw exception) here is an example code from the SyncBlockCache::Grow method:
// Compute the size of the new synctable. Normally, we double it - unless // doing so would create slots with indices too high to fit within the // mask. If so, we create a synctable up to the mask limit. If we're // already at the mask limit, then caller is out of luck. DWORD newSyncTableSize; if (m_SyncTableSize <= (MASK_SYNCBLOCKINDEX >> 1)) { newSyncTableSize = m_SyncTableSize * 2; } else { newSyncTableSize = MASK_SYNCBLOCKINDEX; } if (!(newSyncTableSize > m_SyncTableSize)) // Make sure we actually found room to grow! { COMPlusThrowOM(); }Hash Code
Let’s examine the different cases of GetHashCode. The first one is the case overridden method and I skip on it.
If we remember the start of this post, the hash code is a 26-bit length block (really 26? we will see) that’s stored in the object header. So, in the common case, when no lock is taken on the object, the hash code will be computed and saved in object header.
But if there is a need to create a sync block the hash code will move to the sync block (is already computed) and it will still be a 26 bit hash code or will be computed when required and saved directly in sync block, then it will save in a 32-bit field.
How is the hash code computed?
I can’t be sure, but from the source it’s look like this:
DWORD multiplier = GetThreadId()*4 + 5; m_dwHashCodeSeed = m_dwHashCodeSeed*multiplier + 1; return m_dwHashCodeSeed >> (32-HASHCODE_BITS);And the method must enforce to get result bigger then 0, because 0 means no hash code has been set yet.
When I call GetHashCode what happening?
We search in the object header for BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX & BIT_SBLK_IS_HASHCODE if both set, the hash code is the followed 26 bits in the header.
if just BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX is set, we need to search in the sync block or create a new one if it doesn’t exist.
if BIT_SBLK_IS_HASH_OR_SYNCBLKINDEX is not set, if we are in thin lock, we need to create a sync block and save the hash code there, if not, we need to compute new hash code and save it in the header.
Summarize
Object header is some meta data for the run-time that stores info mainly about lock and hashcode, but also for more things as we saw. The header is limited in size, so when we need, the header contains sync block index to the sync block structure that store all thread synchronization info and more (hash code, app domain index).
Locks can be handled in the header itself (thin lock) or in sync block (fat lock).
Hash code is stored in header itself or in sync block.
for further reading, just look mainly in syncblk.h and syncblk.cpp files in coreclr github. There is more source files the can give info but if you serach you will get them (threading.md, object.cpp, gc.cpp and more).
Advertisements Share this:





