Software rarely, if at all, exists in an informational vacuum. At least, that is the assumption we software engineers can make for most of the applications we develop.
At any scale, every piece of software—in one way or another—communicates with some other software for various reasons: to get reference data from somewhere, to send monitoring signals, to be in touch with other services while being a part of a distributed system, and more.

In this tutorial, you will learn what some of the biggest challenges of integrating large software are and how Apache Camel solves them with ease.
The Problem: Architecture Design for Systems IntegrationYou may have done the following at least once in your software engineering life:
- Identify a fragment of your business logic that should initiate the data sending.
- In the same application layer, write the data transformations in accordance with what the recipient is expecting.
- Wrap the data in a structure that is suitable for transferring and routing over a network.
- Open a connection to a target application using an appropriate driver or a client SDK.
- Send the data and handle the response.
Why is this a bad line of action?
While you have only a few connections of this kind, it remains manageable. With a growing number of relations between systems, the application’s business logic gets mixed with the integration logic, which is about adapting data, compensating for technological differences between two systems, and transferring data to the external system with SOAP, REST, or more exotic requests.
If you were integrating several applications, it would be incredibly difficult to retrace the whole picture of dependencies in such code: Where is the data produced and what services consume it? You’ll have many places where integration logic is duplicated, to boot.
With such an approach, though the task is technically accomplished, we end up with huge issues with the integration’s maintainability and scalability. Quick reorganization of data flows in this system are nigh on impossible, not to mention deeper issues like the lack of monitoring, circuit breaking, laborious data recovery, etc.
This is all especially important when integrating software in the scope of a considerably large enterprise. To deal with the enterprise integration means working with a set of applications, which operate on a wide range of platforms and exist in different locations. The data exchange in such a software landscape is quite demanding. It must meet the high-security standards of the industry and provide a reliable way to transfer data. In an enterprise environment, systems integration requires a separate, thoroughly elaborated architecture design.
This article will introduce you to the unique difficulties faced in software integration as well as provide some experience-driven solutions for integration tasks. We’ll get familiar with Apache Camel, a useful framework that can alleviate the worst bits of an integration developer’s headache. We’ll follow with an example of how Camel can help establish communication in a cluster of microservices powered by Kubernetes.
Integration DifficultiesA widely-used approach to solving the issue is to decouple an integration layer in your application. It can exist within the same application or as an independently running dedicated piece of software—in the latter case called middleware.
What issues do you typically face when developing and supporting middleware? In general, you have the following key items:
- All data channels are unreliable to some extent. Issues stemming from this unreliability may not occur while data intensity is low to moderate. Each storage level from application memory to lower caches and equipment beneath it is subject to potential failure. Some rare errors arise only with huge volumes of data. Even mature production-ready vendor products have unresolved bug tracker issues related to data loss. A middleware system should be able to inform you of these data casualties and supply message redelivery in a timely manner.
- Applications use different protocols and data formats. This means that an integration system is a curtain for data transformations and adapters to other participants and utilizes a variety of technologies. These can include plain REST API calls, but could also be accessing a queue broker, sending CSV orders over FTP, or batch pulling data to a database table. This is a long list and it won’t ever get shorter.
- Changes in data formats and routing rules are inevitable. Each step in the process of an application’s development, which changes the data structure, usually leads to changes in integration data formats and transformations. Sometimes, infrastructure changes with reorganized enterprise data flows are necessary. For example, these changes might happen when introducing a single point of validating reference data that has to process all master data entries throughout the company. With N systems, we may end up having a maximum of almost N^2 connections between them, so the number of places where changes must be applied grows quite fast. It will be like an avalanche. To sustain maintainability, a middleware layer has to provide a clear picture of dependencies with versatile routing and data transformation.
These ideas should be kept in mind when designing the integration and choosing the most suitable middleware solution. One of the possible ways to handle it is to leverage an enterprise service bus (ESB). But ESBs provided by major vendors are generally too heavy and are often more trouble than they’re worth: It’s almost impossible to have a quick start with an ESB, it has quite a steep learning curve, and its flexibility is sacrificed to a long list of features and built-in tools. In my opinion, lightweight open-source integration solutions are far superior—they are more elastic, easy to deploy into the cloud, and easy to scale.
Software integration is not easy to do. Today, as we build microservices architectures and deal with swarms of small services, we also have high expectations for how efficiently they should communicate.
Enterprise Integration PatternsAs might be expected, like software development in general, the development of data routing and transformation involves repetitive operations. Experience in this area has been summarized and systematized by professionals that handle integration problems for quite some time. In the outcome, there’s a set of extracted templates called enterprise integration patterns used for designing data flows. These integration methods were described in the book of the same name by Gregor Hophe and Bobby Wolfe, which is much like the significant Gang of Four’s book but in the area of gluing software.
To give an example, the normalizer pattern introduces a component that maps semantically equal messages that have different data formats to a single canonical model, or the aggregator is an EIP that combines a sequence of messages into one.
Since they are established technology-agnostic abstractions used for solving architectural issues, EIPs help in writing an architecture design, which doesn’t delve into the code level but describes the data flows in sufficient detail. Such notation for describing integration routes not only makes the design concise but also sets a common nomenclature and a common language, which are highly important in the context of solving an integration task with team members from various business areas.
Introducing Apache CamelSeveral years ago, I was building an enterprise integration in a huge grocery retail network with stores in widely distributed locations. I started with a proprietary ESB solution, which turned out to be overly cumbersome to maintain. Then, our team came across Apache Camel, and after doing some “proof of concept” work, we quickly rewrote all our data flows in Camel routes.
Apache Camel can be described as a “mediation router,” a message-oriented middleware framework implementing the list of EIPs, which I familiarized myself with. It makes use of these patterns, supports all common transport protocols, and has a vast set of useful adapters included. Camel enables the handling of a number of integration routines without needing to write your own code.
Apart from this, I would single out the following Apache Camel features:
- Integration routes are written as pipelines made of blocks. It creates a totally transparent picture to help track down the data flows.
- Camel has adapters for many popular APIs. For example, getting data from Apache Kafka, monitoring AWS EC2 instances, integrating with Salesforce—all these tasks can be solved using components available out of the box.
Apache Camel routes can be written in Java or Scala DSL. (An XML configuration is also available but becomes too verbose and has worse debugging capabilities.) It doesn’t impose restrictions on the tech stack of the communicating services, but if you write in Java or Scala, you can embed Camel in an application instead of running it standalone.
The routing notation used by Camel can be described with the following simple pseudocode:
from(Source) .transform(Transformer) .to(Destination)The Source, Transformer, and Destination are endpoints referring to implementation components by their URIs.
What enables Camel to solve the integration problems I described previously? Let’s have a look. Firstly, routing and transformation logic now live only in a dedicated Apache Camel configuration. Secondly, through the succinct and natural DSL in conjunction with the usage of EIPs, a picture of dependencies between systems appears. It’s made of comprehensible abstractions, and the routing logic is easily adjustable. And finally, we don’t have to write heaps of transformation code because appropriate adapters are likely to be included already.

I should add, Apache Camel is a mature framework and gets regular updates. It has a great community and a considerable cumulative knowledge base.
It does have its own disadvantages. Camel shouldn’t be taken as a complex integration suite. It’s a toolbox without high-level features like business process management tools or activity monitors, but it can be used to create such software.
Alternative systems might be, for instance, Spring Integration or Mule ESB. For Spring Integration, though it’s considered to be lightweight, in my experience, putting it together and writing lots of XML configuration files can turn out to be unexpectedly complicated and is hardly an easy way out. Mule ESB is a robust and very functional toolset, but as the name suggests, it’s an enterprise service bus, so it belongs to a different weight category. Mule can be compared with Fuse ESB, a similar product based on Apache Camel with a rich set of features. For me, using Apache Camel for gluing services is a no-brainer today. It’s easy to use and produces a clean description of what goes where—at the same time, it’s functional enough for building complex integrations.
Writing a Sample RouteLet’s start writing the code. We’ll begin from a synchronous data flow that routes messages from a single source to a list of recipients. Routing rules will be written in Java DSL.
We’ll use Maven to build the project. Firstly add the following dependency to the pom.xml:
<dependencies> ... <dependency> <groupId>org.apache.camel</groupId> <artifactId>camel-core</artifactId> <version>2.20.0</version> </dependency> </dependencies>Alternatively, the application can be built on top of the camel-archetype-java archetype.
Camel route definitions are declared in the RouteBuilder.configure method.
public void configure() { errorHandler(defaultErrorHandler().maximumRedeliveries(0)); from("file:orders?noop=true").routeId("main") .log("Incoming File: ${file:onlyname}") .unmarshal().json(JsonLibrary.Jackson, Order.class) // unmarshal JSON to Order class containing List<OrderItem> .split().simple("body.items") // split list to process one by one .to("log:inputOrderItem") .choice() .when().simple("${body.type} == 'Drink'") .to("direct:bar") .when().simple("${body.type} == 'Dessert'") .to("direct:dessertStation") .when().simple("${body.type} == 'Hot Meal'") .to("direct:hotMealStation") .when().simple("${body.type} == 'Cold Meal'") .to("direct:coldMealStation") .otherwise() .to("direct:others"); from("direct:bar").routeId("bar").log("Handling Drink"); from("direct:dessertStation").routeId("dessertStation").log("Handling Dessert"); from("direct:hotMealStation").routeId("hotMealStation").log("Handling Hot Meal"); from("direct:coldMealStation").routeId("coldMealStation").log("Handling Cold Meal"); from("direct:others").routeId("others").log("Handling Something Other"); }In this definition, we create a route that fetches records from the JSON file, splits them into items, and routes to a set of handlers based on message content.
Let’s run it on prepared test data. We’ll get the output:
INFO | Total 6 routes, of which 6 are started INFO | Apache Camel 2.20.0 (CamelContext: camel-1) started in 10.716 seconds INFO | Incoming File: order1.json INFO | Exchange[ExchangePattern: InOnly, BodyType: com.antongoncharov.camel.example.model.OrderItem, Body: OrderItem{id='1', type='Drink', name='Americano', qty='1'}] INFO | Handling Drink INFO | Exchange[ExchangePattern: InOnly, BodyType: com.antongoncharov.camel.example.model.OrderItem, Body: OrderItem{id='2', type='Hot Meal', name='French Omelette', qty='1'}] INFO | Handling Hot Meal INFO | Exchange[ExchangePattern: InOnly, BodyType: com.antongoncharov.camel.example.model.OrderItem, Body: OrderItem{id='3', type='Hot Meal', name='Lasagna', qty='1'}] INFO | Handling Hot Meal INFO | Exchange[ExchangePattern: InOnly, BodyType: com.antongoncharov.camel.example.model.OrderItem, Body: OrderItem{id='4', type='Hot Meal', name='Rice Balls', qty='1'}] INFO | Handling Hot Meal INFO | Exchange[ExchangePattern: InOnly, BodyType: com.antongoncharov.camel.example.model.OrderItem, Body: OrderItem{id='5', type='Dessert', name='Blueberry Pie', qty='1'}] INFO | Handling DessertAs expected, Camel routed messages to the destinations.
Data Transfer ChoicesIn the example above, the interaction between components is synchronous and performed through the application memory. However, there are many more ways to communicate when we deal with separate applications that don’t share memory:
- File exchange. One application produces files of shared data for the another to consume. It’s where the old-school spirit lives. This method of communication has a plethora of consequences: lack of transactions and consistency, poor performance, and isolated coordination between systems. Many developers ended up writing homemade integration solutions to make the process more or less manageable.
- Common database. Have the applications store the data they wish to share in a common schema of a single database. Designing unified schema and handling concurrent access to the tables are the most prominent challenges of this approach. As with the file exchange, it’s easy for this to become a permanent bottleneck.
- Remote API call. Provide an interface to allow an application to interact with another running application, like a typical method call. Applications share functionality via API invocations, but it tightly couples them in the process.
- Messaging. Have each application connect to a common messaging system, and exchange data and invoke behavior asynchronously using messages. Neither the sender nor the recipient has to be up and running at the same time to have the message delivered.
There are more ways to interact, but we should keep in mind that, broadly speaking, there are two types of interaction: synchronous and asynchronous. The first is like calling a function in your code—the execution flow will be waiting until it executes and returns a value. With an asynchronous approach, the same data is sent via an intermediate message queue or subscription topic. An asynchronous remote function call can be implemented as the request-reply EIP.
Asynchronous messaging is not a panacea, though; it involves certain restrictions. You rarely see messaging APIs on the web; synchronous REST services are way more popular. But messaging middleware is widely used in enterprise intranet or distributed system back-end infrastructure.
Using Message QueuesLet’s make our example asynchronous. A software system that manages queues and subscription topics is called a message broker. It’s like an RDBMS for tables and columns. Queues serve as point-to-point integration while topics are for publish-subscribe communication with many recipients. We’ll use Apache ActiveMQ as a JMS message broker because it’s solid and embeddable.
Add the following dependency. Sometimes it’s excessive to add activemq-all, which contains all ActiveMQ jars, to the project, but we’ll keep our application’s dependencies uncomplicated.
<dependency> <groupId>org.apache.activemq</groupId> <artifactId>activemq-all</artifactId> <version>5.15.2</version> </dependency>Then start the broker programmatically. In Spring Boot, we get an autoconfiguration for this by plugging in the spring-boot-starter-activemq Maven dependency.
Run a new message broker with the following commands, specifying only the connector’s endpoint:
BrokerService broker = new BrokerService(); broker.addConnector("tcp://localhost:61616"); broker.start();And add the following configuration snippet to the configure method body:
ConnectionFactory connectionFactory = new ActiveMQConnectionFactory("tcp://localhost:61616"); this.getContext().addComponent("activemq", ActiveMQComponent.jmsComponent(connectionFactory));Now we can update the previous example using message queues. The queues will be automatically created on message delivery.
public void configure() { errorHandler(defaultErrorHandler().maximumRedeliveries(0)); ConnectionFactory connectionFactory = new ActiveMQConnectionFactory("tcp://localhost:61616"); this.getContext().addComponent("activemq", ActiveMQComponent.jmsComponent(connectionFactory)); from("file:orders?noop=true").routeId("main") .log("Incoming File: ${file:onlyname}") .unmarshal().json(JsonLibrary.Jackson, Order.class) // unmarshal JSON to Order class containing List<OrderItem> .split().simple("body.items") // split list to process one by one .to("log:inputOrderItem") .choice() .when().simple("${body.type} == 'Drink'") .to("activemq:queue:bar") .when().simple("${body.type} == 'Dessert'") .to("activemq:queue:dessertStation") .when().simple("${body.type} == 'Hot Meal'") .to("activemq:queue:hotMealStation") .when().simple("${body.type} == 'Cold Meal'") .to("activemq:queue:coldMealStation") .otherwise() .to("activemq:queue:others"); from("activemq:queue:bar").routeId("barAsync").log("Drinks"); from("activemq:queue:dessertStation").routeId("dessertAsync").log("Dessert"); from("activemq:queue:hotMealStation").routeId("hotMealAsync").log("Hot Meals"); from("activemq:queue:coldMealStation").routeId("coldMealAsync").log("Cold Meals"); from("activemq:queue:others").routeId("othersAsync").log("Others"); }All right, now the interaction has become asynchronous. Potential consumers of this data may access it when they’re ready to. This is an example of loose coupling, which we try to achieve in a reactive architecture. Unavailability of one of the services won’t block the others. Moreover, a consumer may scale and read from the queue in parallel. The queue itself may scale and be partitioned. Persistent queues can store the data on the disk, waiting to be processed, even when all participants went down. Consequently, this system is more fault-tolerant.
An astonishing fact is that CERN uses Apache Camel and ActiveMQ to monitor the systems of the Large Hadron Collider (LHC). There’s also an interesting master’s thesis explaining the choice of an appropriate middleware solution for this task. So, as they say in the keynote, “No JMS—no particle physics!”
MonitoringIn the previous example, we created the data channel between two services. It’s an additional potential point of failure in an architecture, so we have to look after it. Let’s take a look at what monitoring features Apache Camel provides. Basically, it exposes statistical information about its routes through the MBeans, accessible by JMX. ActiveMQ exposes queue stats in the same way.
Let’s turn on the JMX server in the application, to enable it to run with the command line options:
-Dorg.apache.camel.jmx.createRmiConnector=true -Dorg.apache.camel.jmx.mbeanObjectDomainName=org.apache.camel -Dorg.apache.camel.jmx.rmiConnector.registryPort=1099 -Dorg.apache.camel.jmx.serviceUrlPath=camelNow run the application so that the route has done its job. Open the standard jconsole tool and connect to the application process. Connect to the URL service:jmx:rmi:///jndi/rmi://localhost:1099/camel. Go to the org.apache.camel domain in the MBeans tree.

We can see that everything about routing is under control. We have the number of in-flight messages, the error count, and the message count in the queues. This information can be pipelined to some monitoring toolset with rich functionality like Graphana or Kibana. You can do this by implementing the well-known ELK stack.
There’s also a pluggable and extendable web console which provides a UI for managing Camel, ActiveMQ, and many more, called hawt.io.
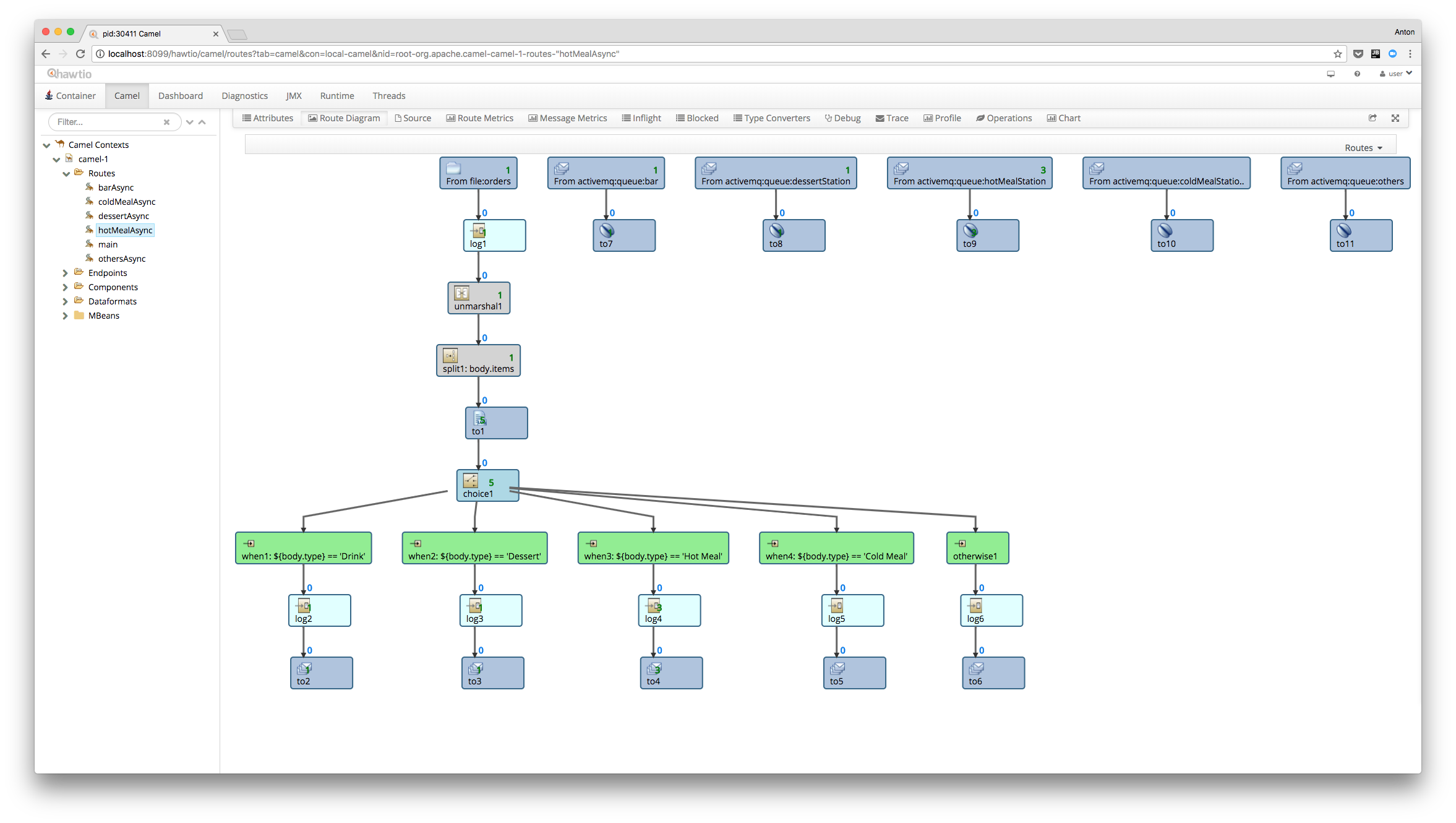
Apache Camel has quite broad functionality for writing test routes with mock components. It’s a powerful tool, but writing separate routes just for testing is a time-consuming process. It would be more efficient to run tests on production routes without modifying their pipeline. Camel has this feature and can be implemented using the AdviceWith component.
Let’s enable test logic in our example and run a sample test.
<dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.camel</groupId> <artifactId>camel-test</artifactId> <version>2.20.0</version> <scope>test</scope> </dependency>The test class is:
public class AsyncRouteTest extends CamelTestSupport { @Override protected RouteBuilder createRouteBuilder() throws Exception { return new AsyncRouteBuilder(); } @Before public void mockEndpoints() throws Exception { context.getRouteDefinition("main").adviceWith(context, new AdviceWithRouteBuilder() { @Override public void configure() throws Exception { // we substitute all actual queues with mock endpoints mockEndpointsAndSkip("activemq:queue:bar"); mockEndpointsAndSkip("activemq:queue:dessertStation"); mockEndpointsAndSkip("activemq:queue:hotMealStation"); mockEndpointsAndSkip("activemq:queue:coldMealStation"); mockEndpointsAndSkip("activemq:queue:others"); // and replace the route's source with test endpoint replaceFromWith("file://testInbox"); } }); } @Test public void testSyncInteraction() throws InterruptedException { String testJson = "{\"id\": 1, \"order\": [{\"id\": 1, \"name\": \"Americano\", \"type\": \"Drink\", \"qty\": \"1\"}, {\"id\": 2, \"name\": \"French Omelette\", \"type\": \"Hot Meal\", \"qty\": \"1\"}, {\"id\": 3, \"name\": \"Lasagna\", \"type\": \"Hot Meal\", \"qty\": \"1\"}, {\"id\": 4, \"name\": \"Rice Balls\", \"type\": \"Hot Meal\", \"qty\": \"1\"}, {\"id\": 5, \"name\": \"Blueberry Pie\", \"type\": \"Dessert\", \"qty\": \"1\"}]}"; // get mocked endpoint and set an expectation MockEndpoint mockEndpoint = getMockEndpoint("mock:activemq:queue:hotMealStation"); mockEndpoint.expectedMessageCount(3); // simulate putting file in the inbox folder template.sendBodyAndHeader("file://testInbox", testJson, Exchange.FILE_NAME, "test.json"); //checks that expectations were met assertMockEndpointsSatisfied(); } }Now run tests for the application with mvn test. We can see that our route has successfully been executed with the testing advice. There are no messages passed through the actual queues and the tests have been passed.
INFO | Route: main started and consuming from: file://testInbox <...> INFO | Incoming File: test.json <...> INFO | Asserting: mock://activemq:queue:hotMealStation is satisfied Using Apache Camel with Kubernetes ClusterOne of the integration issues today is that applications are no longer static. In a cloud infrastructure, we deal with virtual services that run on multiple nodes at the same time. It enables the microservices architecture with a net of small, lightweight services interacting among themselves. These services have an unreliable lifetime, and we have to discover them dynamically.
Gluing cloud services together is a task that can be solved with Apache Camel. It’s especially interesting because of the EIP flavor and the fact that Camel has plenty of adapters and supports a wide range of protocols. The recent version 2.18 adds the ServiceCall component, which introduces a feature of calling an API and resolving its address via cluster discovery mechanisms. Currently, it supports Consul, Kubernetes, Ribbon, etc. Some examples of code, where ServiceCall is configured with Consul, can be found easily. We’ll be using Kubernetes here because it’s my favorite clustering solution.
The integration schema will be as the following:
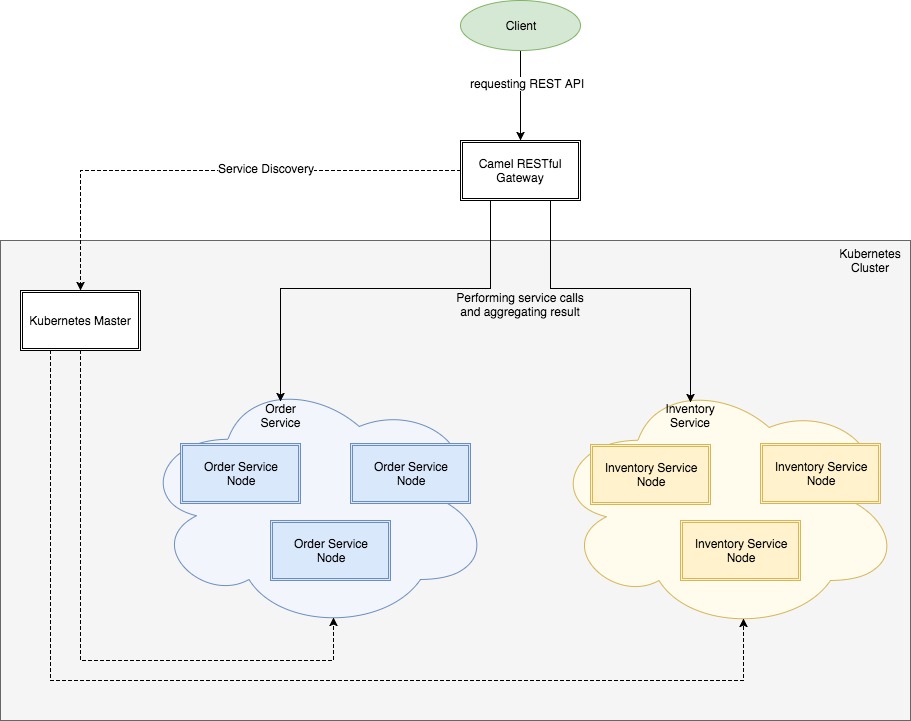
The Order service and the Inventory service will be a couple of trivial Spring Boot applications returning static data. We aren’t tied to a particular tech stack here. These services are producing the data we want to process.
Order Service controller:
@RestController public class OrderController { private final OrderStorage orderStorage; @Autowired public OrderController(OrderStorage orderStorage) { this.orderStorage = orderStorage; } @RequestMapping("/info") public String info() { return "Order Service UUID = " + OrderApplication.serviceID; } @RequestMapping("/orders") public List<Order> getAll() { return orderStorage.getAll(); } @RequestMapping("/orders/{id}") public Order getOne(@PathVariable Integer id) { return orderStorage.getOne(id); } }It produces data in the format:
[{"id":1,"items":[2,3,4]},{"id":2,"items":[5,3]}]The Inventory service controller is absolutely similar to Order service’s:
@RestController public class InventoryController { private final InventoryStorage inventoryStorage; @Autowired public InventoryController(InventoryStorage inventoryStorage) { this.inventoryStorage = inventoryStorage; } @RequestMapping("/info") public String info() { return "Inventory Service UUID = " + InventoryApplication.serviceID; } @RequestMapping("/items") public List<InventoryItem> getAll() { return inventoryStorage.getAll(); } @RequestMapping("/items/{id}") public InventoryItem getOne(@PathVariable Integer id) { return inventoryStorage.getOne(id); } }InventoryStorage is a generic repository that holds data. In this example, it returns static pre-defined objects, which are marshaled to the following format.
[{"id":1,"name":"Laptop","description":"Up to 12-hours battery life","price":499.9},{"id":2,"name":"Monitor","description":"27-inch, response time: 7ms","price":200.0},{"id":3,"name":"Headphones","description":"Soft leather ear-cups","price":29.9},{"id":4,"name":"Mouse","description":"Designed for comfort and portability","price":19.0},{"id":5,"name":"Keyboard","description":"Layout: US","price":10.5}]Let’s write a gateway route connecting them, but without ServiceCall at this step:
rest("/orders") .get("/").description("Get all orders with details").outType(TestResponse.class) .route() .setHeader("Content-Type", constant("application/json")) .setHeader("Accept", constant("application/json")) .setHeader(Exchange.HTTP_METHOD, constant("GET")) .removeHeaders("CamelHttp*") .to("http4://localhost:8082/orders?bridgeEndpoint=true") .unmarshal(formatOrder) .enrich("direct:enrichFromInventory", new OrderAggregationStrategy()) .to("log:result") .endRest(); from("direct:enrichFromInventory") .transform().simple("${null}") .setHeader("Content-Type", constant("application/json")) .setHeader("Accept", constant("application/json")) .setHeader(Exchange.HTTP_METHOD, constant("GET")) .removeHeaders("CamelHttp*") .to("http4://localhost:8081/items?bridgeEndpoint=true") .unmarshal(formatInventory);Now imagine that each service is no longer a specific instance but a cloud of instances operating as one. We’ll use Minikube to try the Kubernetes cluster locally.
Configure the network routes to see Kubernetes nodes locally (the given example is for a Mac/Linux environment):
# remove existing routes sudo route -n delete 10/24 > /dev/null 2>&1 # add routes sudo route -n add 10.0.0.0/24 $(minikube ip) # 172.17.0.0/16 ip range is used by docker in minikube sudo route -n add 172.17.0.0/16 $(minikube ip) ifconfig 'bridge100' | grep member | awk '{print $2}’ # use interface name from the output of the previous command # needed for xhyve driver, which I'm using for testing sudo ifconfig bridge100 -hostfilter en5Wrap the services in Docker containers with a Dockerfile config like this:
FROM openjdk:8-jdk-alpine VOLUME /tmp ADD target/order-srv-1.0-SNAPSHOT.jar app.jar ADD target/lib lib ENV JAVA_OPTS="" ENTRYPOINT exec java $JAVA_OPTS -Djava.security.egd=file:/dev/./urandom -jar /app.jarBuild and push the service images to the Docker registry. Now run the nodes in the local Kubernetes cluster.
Kubernetes.yaml deployment configuration:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: inventory spec: replicas: 3 selector: matchLabels: app: inventory template: metadata: labels: app: inventory spec: containers: - name: inventory image: inventory-srv:latest imagePullPolicy: Never ports: - containerPort: 8081Expose these deployments as services in cluster:
kubectl expose deployment order-srv --type=NodePort kubectl expose deployment inventory-srv --type=NodePortNow we can check if requests are served by randomly chosen nodes from the cluster. Run curl -X http://192.168.99.100:30517/info sequentially several times to access minikube NodePort for exposed service (using your host and port). In the output, we’re seeing that we’ve achieved request balancing.
Inventory Service UUID = 22f8ca6b-f56b-4984-927b-cbf9fcf81da5 Inventory Service UUID = b7a4d326-1e76-4051-a0a6-1016394fafda Inventory Service UUID = b7a4d326-1e76-4051-a0a6-1016394fafda Inventory Service UUID = 22f8ca6b-f56b-4984-927b-cbf9fcf81da5 Inventory Service UUID = 50323ddb-3ace-4424-820a-6b4e85775af4Add camel-kubernetes and camel-netty4-http dependencies to the project’s pom.xml. Then configure the ServiceCall component to use Kubernetes master node discovery shared for all service calls among route definitions:
KubernetesConfiguration kubernetesConfiguration = new KubernetesConfiguration(); kubernetesConfiguration.setMasterUrl("https://192.168.64.2:8443"); kubernetesConfiguration.setClientCertFile("/Users/antongoncharov/.minikube/client.crt"); kubernetesConfiguration.setClientKeyFile("/Users/antongoncharov/.minikube/client.key"); kubernetesConfiguration.setNamespace("default”); ServiceCallConfigurationDefinition config = new ServiceCallConfigurationDefinition(); config.setServiceDiscovery(new KubernetesClientServiceDiscovery(kubernetesConfiguration)); context.setServiceCallConfiguration(config);The ServiceCall EIP complements Spring Boot well. Most of the options can be configured directly in the application.properties file.
Empower the Camel route with the ServiceCall component:
rest("/orders") .get("/").description("Get all orders with details").outType(TestResponse.class) .route() .hystrix() .setHeader("Content-Type", constant("application/json")) .setHeader("Accept", constant("application/json")) .setHeader(Exchange.HTTP_METHOD, constant("GET")) .removeHeaders("CamelHttp*") .serviceCall("customer-srv","http4:customer-deployment?bridgeEndpoint=true") .unmarshal(formatOrder) .enrich("direct:enrichFromInventory", new OrderAggregationStrategy()) .to("log:result") .endRest(); from("direct:enrichFromInventory") .transform().simple("${null}") .setHeader("Content-Type", constant("application/json")) .setHeader("Accept", constant("application/json")) .setHeader(Exchange.HTTP_METHOD, constant("GET")) .removeHeaders("CamelHttp*") .serviceCall("order-srv","http4:order-srv?bridgeEndpoint=true") .unmarshal(formatInventory);We also activated Circuit Breaker in the route. It’s an integration hook that allows pausing of remote system calls in case of delivery errors or recipient unavailability. This is designed to avoid cascade system failure. The Hystrix component helps achieve this by implementing the Circuit Breaker pattern.
Let’s run it and send a test request; we’ll get the response aggregated from both services.
[{"id":1,"items":[{"id":2,"name":"Monitor","description":"27-inch, response time: 7ms","price":200.0},{"id":3,"name":"Headphones","description":"Soft leather ear-cups","price":29.9},{"id":4,"name":"Mouse","description":"Designed for comfort and portability","price":19.0}]},{"id":2,"items":[{"id":5,"name":"Keyboard","description":"Layout: US","price":10.5},{"id":3,"name":"Headphones","description":"Soft leather ear-cups","price":29.9}]}]The result is as expected.
Other Use CasesI showed how Apache Camel can integrate microservices in a cluster. What are other uses of this framework? In general, it’s useful in any place where rule-based routing may be a solution. For instance, Apache Camel can be a middleware for the Internet of Things with the Eclipse Kura adapter. It can handle monitoring by ferrying log signals from various components and services, like in the CERN system. It can also be an integration framework for enterprise SOA or be a pipeline for batch data processing, although it doesn’t compete well with Apache Spark in this area.
ConclusionYou can see that systems integration isn’t an easy process. We’re lucky because a lot of experience has been gathered. It’s important to apply it correctly to build flexible and fault-tolerant solutions.
To ensure correct application, I recommend having a checklist of important integration aspects. Must-have items include:
- Is there a separate integration layer?
- Are there tests for integration?
- Do we know the expected peak data intensity?
- Do we know the expected data delivery time?
- Does message correlation matter? What if a sequence breaks?
- Should we do it in a synchronous or asynchronous way?
- Where do formats and routing rules change more frequently?
- Do we have ways to monitor the process?
In this article, we tried Apache Camel, a lightweight integration framework, which helps save time and effort when solving integration problems. As we showed, it can serve as a tool, supporting the relevant microservice architecture by taking full responsibility for data exchange between microservices.
If you’re interested in learning more about Apache Camel, I highly recommend the book “Camel in Action” by the framework’s creator, Claus Ibsen. Official documentation is available at camel.apache.org.
UNDERSTANDING THE BASICS What is an EIP?An EIP, short for enterprise integration pattern, is a software pattern that is used for designing data flows between different pieces of enterprise software.
What is Apache Camel?Apache Camel is a “mediation router”: a message-oriented middleware framework implementing the enterprise integration patterns. It makes use of these patterns along with supporting all common transport protocols and having a vast set of useful adapters included.
About the author Anton Goncharov, Russia
MEMBER SINCE JUNE 20, 2016
Anton is a skilled full-stack software developer and a passionate learner. He has extensive expertise in designing robust and scalable applications—his work experience involves creating and supporting several large-scale distributed systems. He’s fluent in Java/Spring stack and experienced in JavaScript development.
Anton Goncharov, Russia
MEMBER SINCE JUNE 20, 2016
Anton is a skilled full-stack software developer and a passionate learner. He has extensive expertise in designing robust and scalable applications—his work experience involves creating and supporting several large-scale distributed systems. He’s fluent in Java/Spring stack and experienced in JavaScript development.
Originally appeared on Toptal.
Advertisements Share this:





